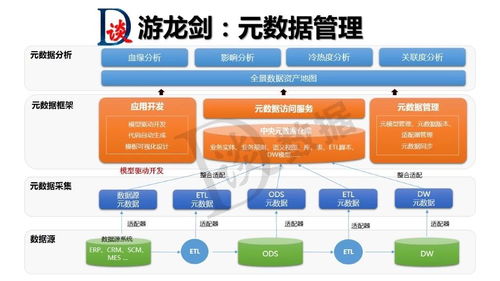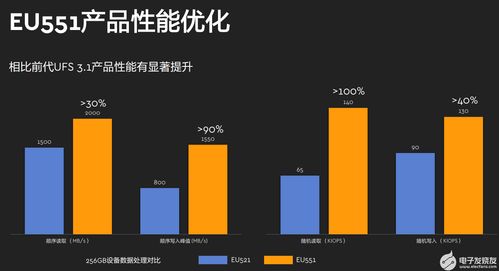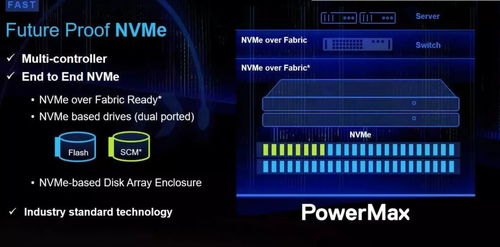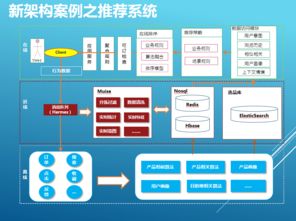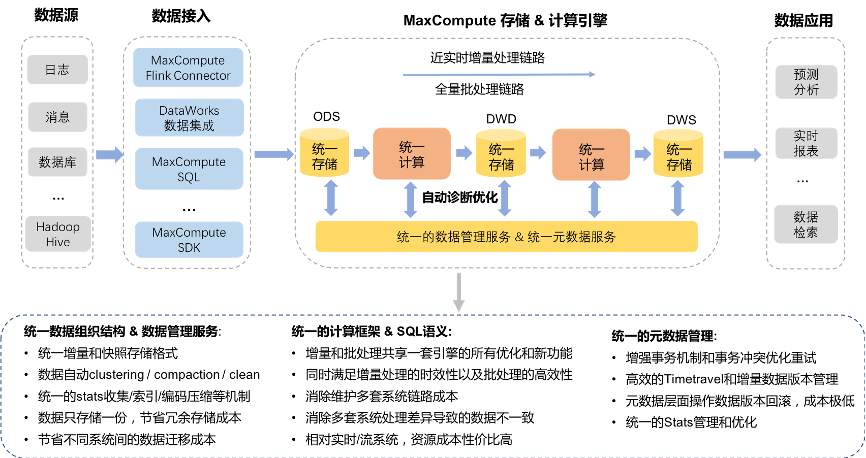
随着大数据技术的演进,企业对数据处理时效性的要求日益提升,传统T+1的批处理模式已难以满足实时分析与决策的需求。阿里云MaxCompute作为领先的大数据计算平台,积极拥抱湖仓一体架构,并融合近实时增量处理能力,构建了一套高效、稳定且灵活的数据处理与存储支持服务体系,为企业数字化转型注入了新动力。
一、 核心理念:湖仓一体的融合与演进
MaxCompute的湖仓一体架构并非简单地将数据湖与数据仓库叠加,而是通过深度整合,实现了两者的优势互补。其核心在于:
- 统一存储层:以开放格式(如Parquet、ORC)存储数据,支持对存储在对象存储(OSS)等上的数据直接进行分析,打破了数据孤岛,实现了数据在湖与仓之间的自由流动与统一管理。
- 统一元数据与权限:提供统一的元数据服务和细粒度的数据安全与权限管控,确保数据在湖、仓以及不同计算引擎间访问的一致性、安全性与可治理性。
- 统一计算引擎:MaxCompute SQL、Spark、Flink等多种计算引擎可无缝对接同一份数据,根据场景选择最合适的处理模式,从批量ETL到交互式查询,再到流处理,实现计算范式的统一。
二、 近实时增量处理的技术架构
为应对分钟级甚至秒级延迟的数据处理需求,MaxCompute在湖仓一体基础上,构建了高效的近实时增量处理技术栈。
1. 增量数据高速摄入通道
- 数据源对接:无缝集成数据库Binlog(如MySQL)、消息队列(如Kafka、RocketMQ)、日志文件等多种实时数据源。
- 流式摄入服务:通过Flink CDC、DataHub等组件,以极低的延迟将增量数据持续、稳定地摄入到MaxCompute的存储层,并保证数据的Exactly-Once语义和顺序性。
2. 增量存储与表格式
- 增量文件组织:采用如Hudi、Iceberg等开源表格式或自研优化格式来管理数据。这些格式支持增量文件的快速追加、小文件合并、ACID事务以及时间旅行查询,是近实时处理的基石。
- 分层存储与生命周期管理:热数据(最新增量)与温冷数据采用不同的存储介质和压缩策略,在保证查询性能的同时优化存储成本。系统自动管理数据生命周期,完成从实时层到明细层、汇总层的平滑流转。
3. 近实时计算与同步
- 微批与流计算融合:核心在于“微批”(Micro-batch)处理模式。系统以固定的短周期(如1-5分钟)调度处理任务,对上一个周期内到达的增量数据进行计算。这既保证了较低的端到端延迟,又继承了批处理框架的容错性和状态管理优势。
- 增量物化视图与聚合:支持创建基于增量数据的物化视图,系统自动维护视图的刷新,使得下游应用能够近乎实时地查询到最新的聚合结果,极大提升了宽表构建和指标计算的效率。
- Lambda架构简化:通过一套架构同时处理实时流和离线历史数据,避免了维护两套系统(流、批)的复杂性,实现了架构的简化和数据的一致性。
4. 统一服务与数据输出
- 一体化查询服务:通过MaxCompute SQL或兼容Spark SQL的接口,用户可以透明地查询包括最新增量在内的全量数据,无需感知底层是实时数据还是历史数据。
- 多模数据服务:处理后的数据可灵活地输出至各类服务,如同步至OLAP数据库(如Hologres、ADB)供交互式分析,推送至缓存或消息队列供在线服务调用,或直接以文件形式供数据科学平台使用。
三、 数据处理与存储支持服务全景
MaxCompute围绕上述架构,提供了一站式的数据处理与存储支持服务:
- 弹性可扩展的计算与存储:计算与存储资源彻底解耦,均可独立弹性伸缩,从容应对业务峰值,并实现成本最优。
- 企业级可靠性与运维:提供高达99.95%的可用性SLA,具备跨可用区容灾、数据多重备份、自动故障恢复等能力,并配备完善的监控、告警与智能运维工具,降低运维负担。
- 全链路数据治理:内置数据质量、数据地图、数据血缘、成本优化等治理工具,确保从数据摄入、处理到服务全链路的可靠性、可追溯性与成本可控性。
- 开放生态集成:与阿里云DataWorks(数据开发与治理)、Flink、OSS等产品深度集成,同时兼容开源生态,保障用户技术栈的平滑过渡与扩展。
###
MaxCompute的湖仓一体近实时增量处理架构,代表了大数据平台向实时化、智能化、一体化演进的重要方向。它通过统一存储、统一计算、统一服务,不仅解决了数据时效性的核心痛点,更简化了架构,降低了运维复杂度,为企业构建实时数据仓库、进行实时监控预警、实现用户实时画像等场景提供了坚实的技术基础。随着技术的持续迭代,这一架构将助力更多企业在数据驱动的道路上跑出“加速度”。